Ayush Tewari
at2164@cam.ac.uk

I am an Assistant Professor at the University of Cambridge. My research interests lie in visual perception. I develop methods that infer rich structured representations of the visual world from images and videos, much like the mental models humans infer to interact with and navigate their surroundings.
I was previously a postdoctoral researcher at MIT CSAIL with Bill Freeman, Josh Tenenbaum, and Vincent Sitzmann. I completed my Ph.D. at the Max Planck Institute for Informatics with Christian Theobalt.
PhD Students



Publications
Efficient Camera-Controlled Video Generation of Static Scenes via Sparse Diffusion and 3D Rendering
arXiv, 2026
Jieying Chen, Jeffrey Hu, Joan Lasenby, and
[project page] [paper]
VDAWorld: World Modelling via VLM-Directed Abstraction and Simulation
arXiv, 2025
Felix O'Mahony, Roberto Cipolla, and
[project page] [paper]
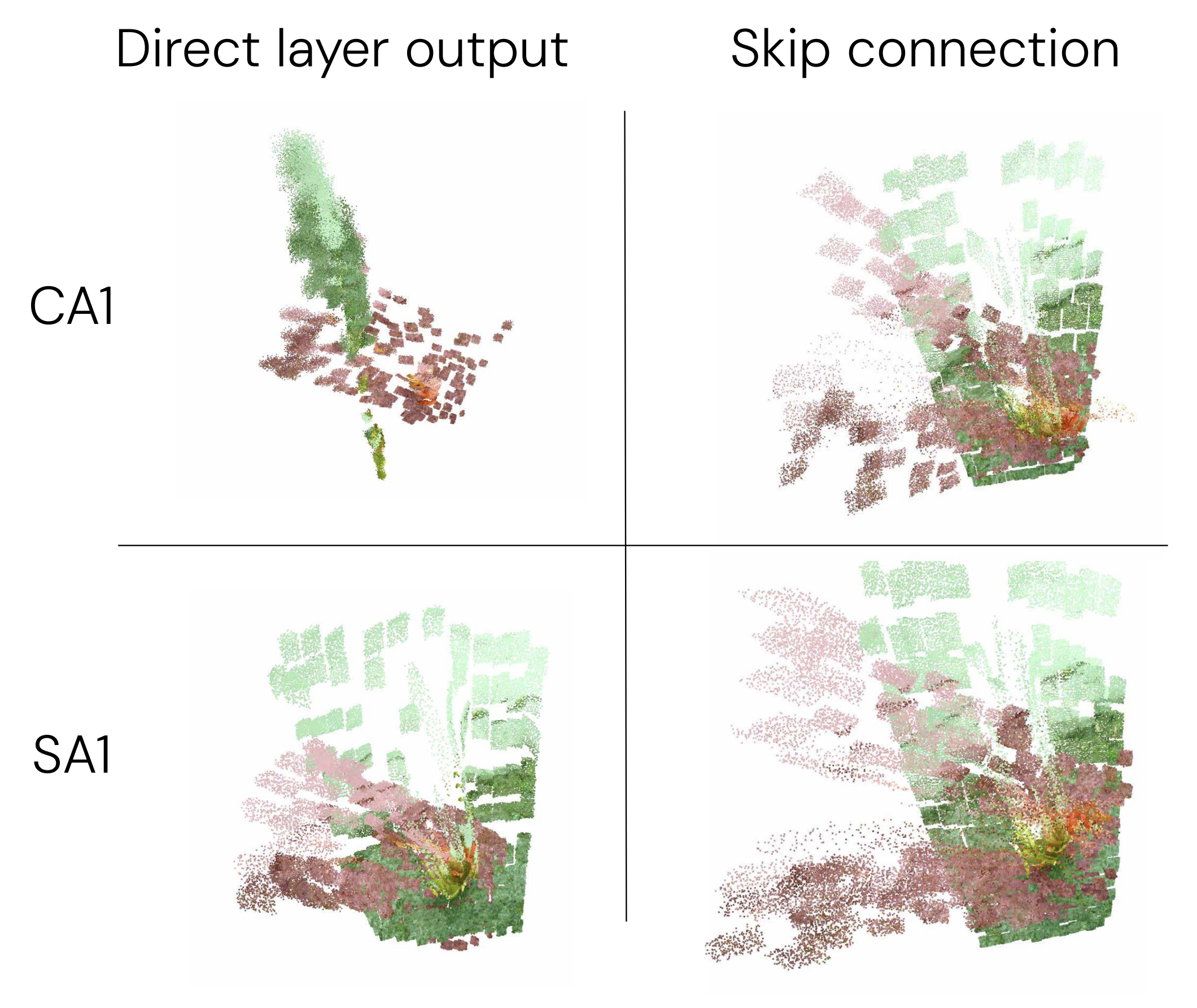
Understanding Multi-view Transformers
ICCV 2025 End-to-End Learning Workshop
Julien Gaubil*, Michal Stary*, , and Vincent Sitzmann (* equal contribution)
[paper] [code]
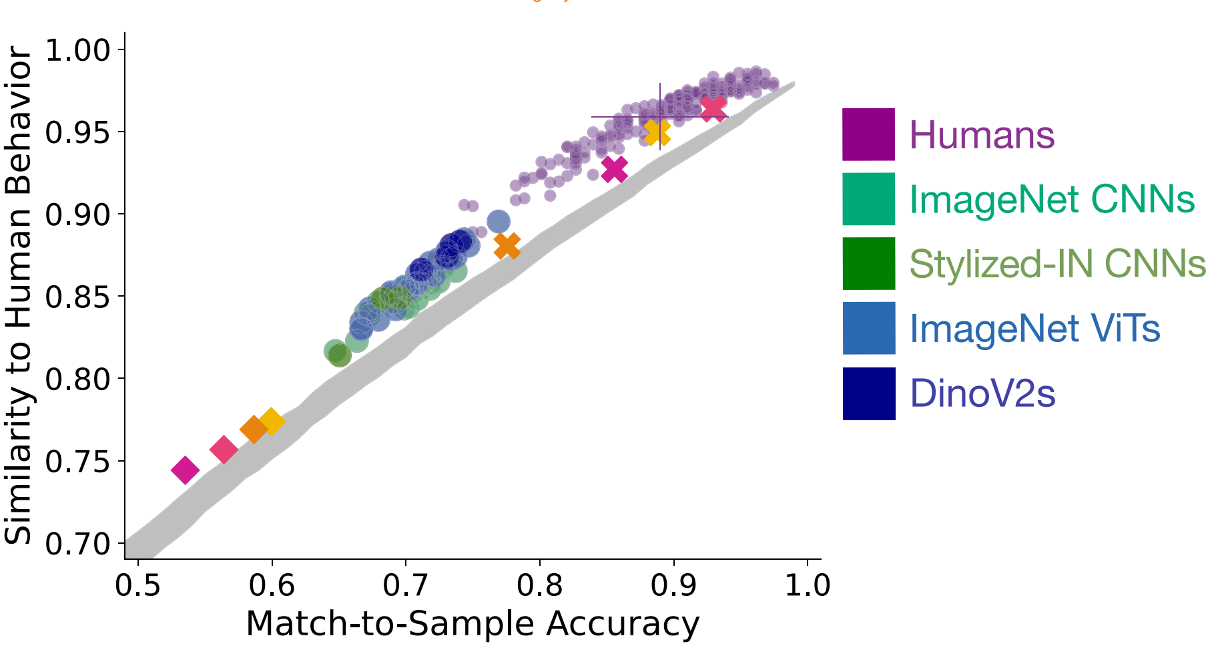
Approximating Human-Level 3D Visual Inferences With Deep Neural Networks
Open Mind 2025
Thomas P. O’Connell, Tyler Bonnen, Yoni Friedman, , Vincent Sitzmann, Joshua B. Tenenbaum, and Nancy Kanwisher
[paper]
FlowMap: High-Quality Camera Poses, Intrinsics, and Depth via Gradient Descent
3DV 2025
Cameron Smith*, David Charatan*, , and Vincent Sitzmann (* equal contribution)
[project page] [paper]

Manifold Sampling for Differentiable Uncertainty in Radiance Fields
SIGGRAPH Asia 2024
Linjie Lyu, , Marc Habermann, Shunsuke Saito, Michael Zollhoefer, Thomas Leimkuehler, and Christian Theobalt
[project page] [paper]
PickScan: Object discovery and reconstruction from handheld interactions
IROS 2024
Vincent van der Brugge, Marc Pollefeys, Joshua B. Tenenbaum, Krishna Murthy Jatavallabhula†, and † († equal advising)
[project page] [paper]

COCO-Periph: Bridging the Gap Between Human and Machine Perception in the Periphery
ICLR 2024
Anne Harrington, Vasha DuTell, Mark Hamilton, , Simon Stent, William T. Freeman, and Ruth Rosenholtz
[project page] [paper]
Diffusion with Forward Models: Solving Stochastic Inverse Problems Without Direct Supervision
NeurIPS 2023 (Spotlight)
*, Tianwei Yin*, George Cazenavette, Semon Rezchikov, Joshua B. Tenenbaum, Fredo Durand, William T. Freeman, and Vincent Sitzmann (* equal contribution)
[project page] [paper] [code]
FlowCam: Training Generalizable 3D Radiance Fields without Camera Poses via Pixel-Aligned Scene Flow
NeurIPS 2023
Cameron Smith, Yilun Du, , and Vincent Sitzmann
[project page] [paper] [code]
Diffusion Posterior Illumination for Ambiguity-aware Inverse Rendering
SIGGRAPH Asia 2023
Linjie Lyu, , Marc Habermann, Shunsuke Saito, Michael Zollhoefer, Thomas Leimkuehler, and Christian Theobalt
[project page] [paper]
AvatarStudio: Text-driven Editing of 3D Dynamic Human Head Avatars
SIGGRAPH Asia 2023
Mohit Mendiratta, Xingang Pan, Mohamed Elgharib, Kartik Teotia, Mallikarjun B R, , Vladislav Golyanik, Adam Kortylewski, and Christian Theobalt
[project page] [paper]
ModalNeRF: Neural Modal Analysis and Synthesis for Free-Viewpoint Navigation in Dynamically Vibrating Scenes
EGSR, Computer Graphics Forum 2023
Automne Petitjean, Yohan Poirier-Ginter, , Guillaume Cordonnier, and George Drettakis
[project page] [paper]
Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold
SIGGRAPH 2023
Xingang Pan, , Thomas Leimkuehler, Lingjie Liu, Abhimitra Meka, and Christian Theobalt
[project page] [paper] [code]
Learning to Render Novel Views from Wide-Baseline Stereo Pairs
CVPR 2023
Yilun Du, Cameron Smith, †, and Vincent Sitzmann† († equal advising)
[project page] [paper] [code]
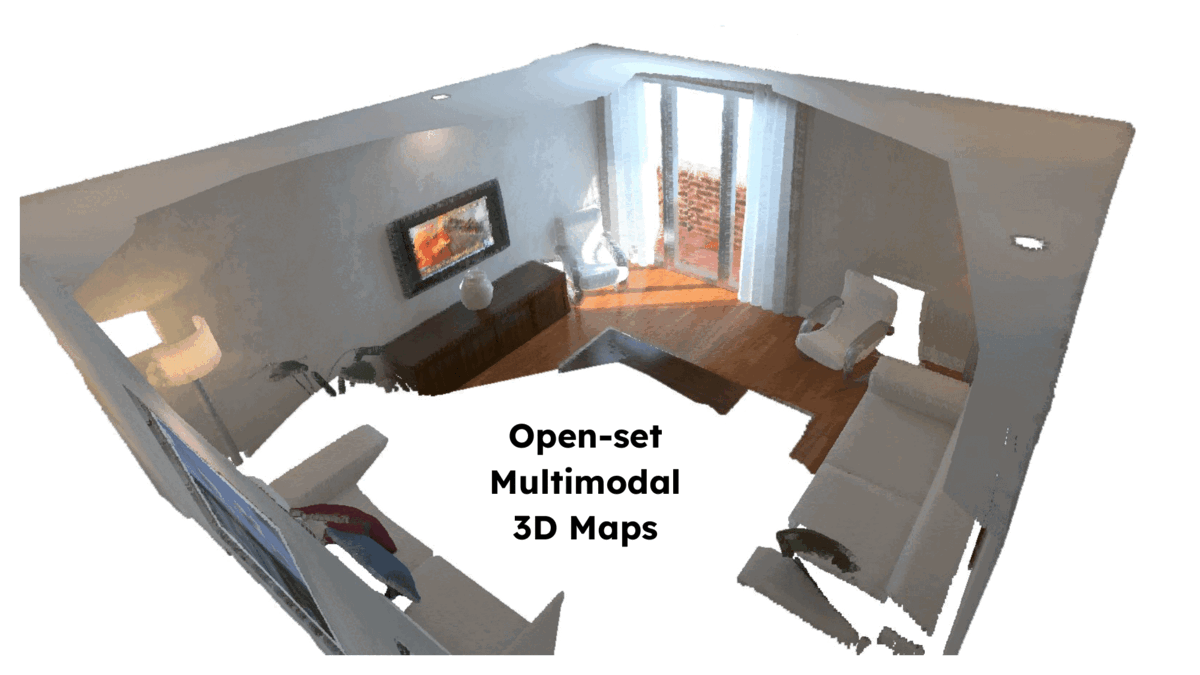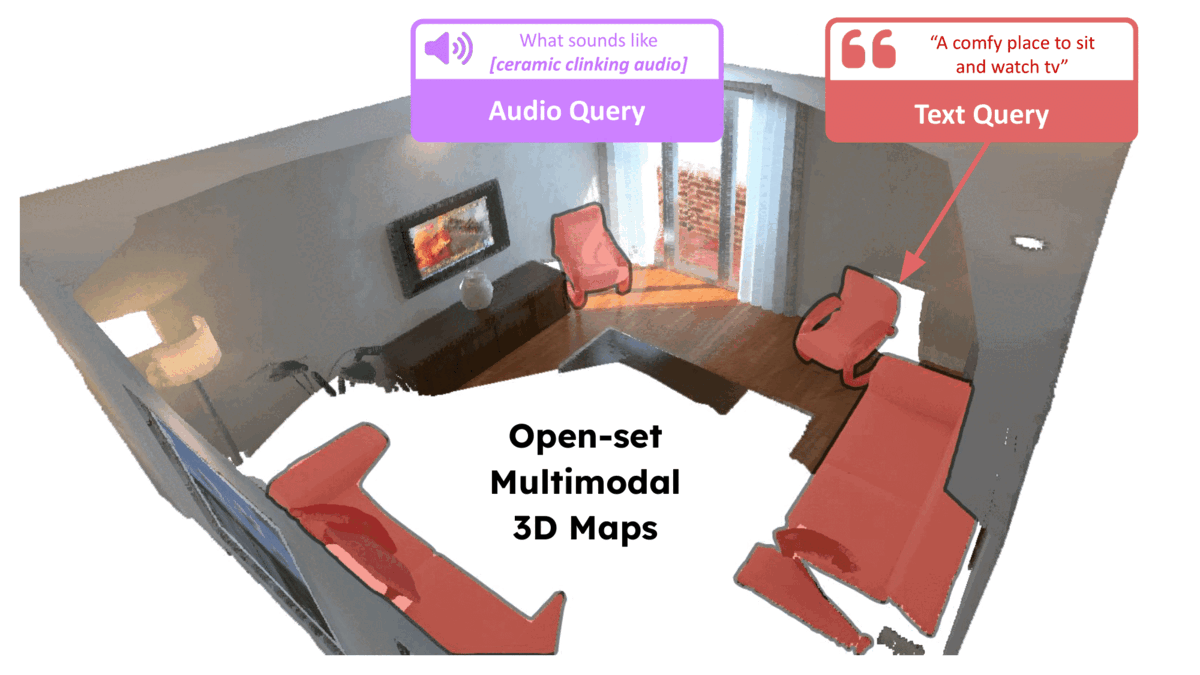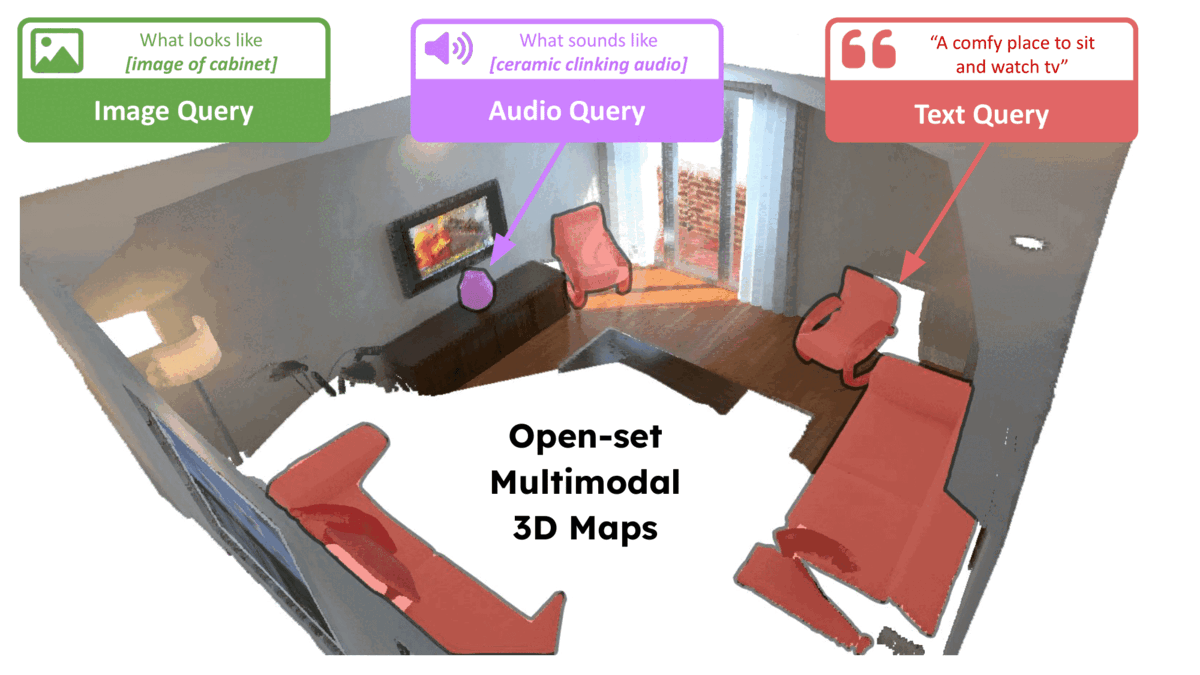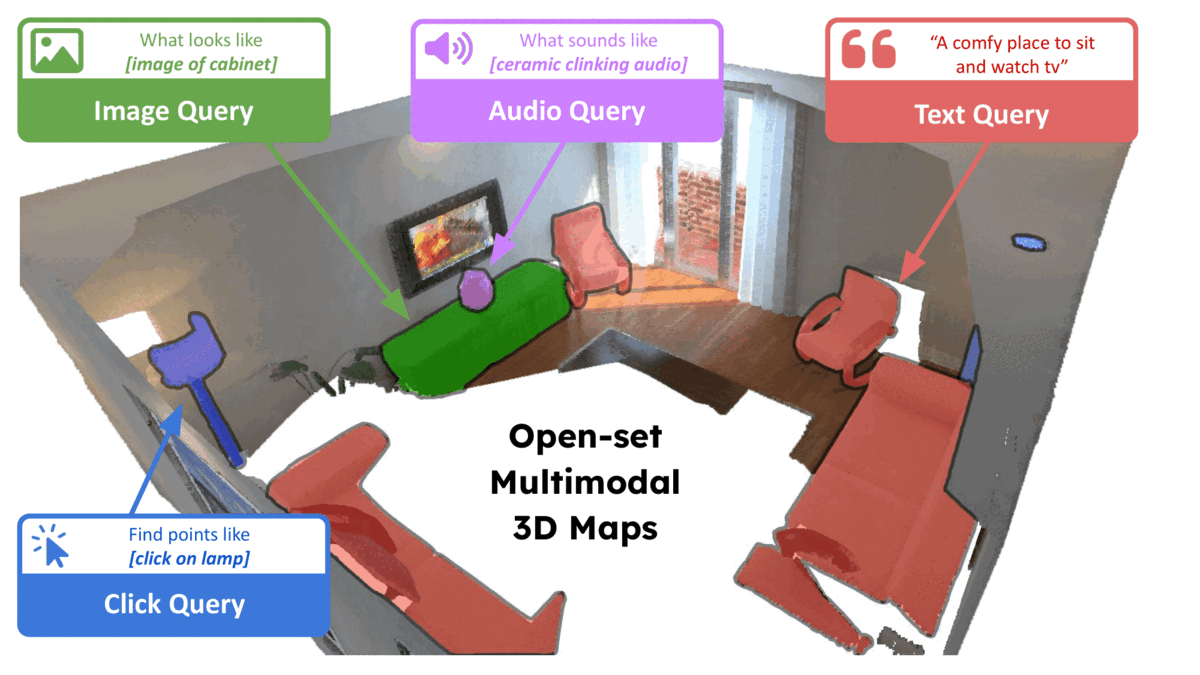
ConceptFusion: Open-set Multimodal 3D Mapping
RSS 2023
Krishna Murthy Jatavallabhula, ..., , et. al
[project page] [paper]

Neural Groundplans: Persistent Neural Scene Representations from a Single Image
ICLR 2023
Prafull Sharma, , Yilun Du, Sergey Zakharov, Rares Ambrus, Adrien Gaidon, William T. Freeman, Fredo Durand, Joshua B. Tenenbaum, and Vincent Sitzmann
[project page] [paper]
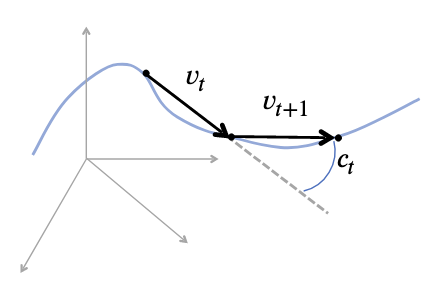
Exploring Perceptual Straightness in Learned Visual Representations
ICLR 2023
Anne Harrington, Vasha DuTell, , Mark Hamilton, Simon Stent, Ruth Rosenholtz, and William T. Freeman
[paper]

Neural Radiance Transfer Fields for Relightable Novel-view Synthesis with Global Illumination
ECCV 2022 (Oral Presentation)
Linjie Lyu, , Thomas Leimkuehler, Marc Habermann, and Christian Theobalt
[project page] [paper]

GAN2X: Non-Lambertian Inverse Rendering of Image GANs
3DV 2022
Xingang Pan, , Lingjie Liu, and Christian Theobalt
[project page] [paper]

VoRF: Volumetric Relightable Faces
BMVC 2022 (Oral Presentation, Best Paper Honorable Mention)
Pramod Rao, Mallikarjun B R, Gereon Fox, Tim Weyrich, Bernd Bickel, Hanspeter Pfister, Wojciech Matusik, , Christian Theobalt, and Mohamed Elgharib
[project page] [paper]

Disentangled3D: Learning a 3D Generative Model with Disentangled Geometry and Appearance from Monocular Images
CVPR 2022
, Mallikarjun B R, Xingang Pan, Ohad Fried, Maneesh Agrawala, and Christian Theobalt
[project page] [paper]
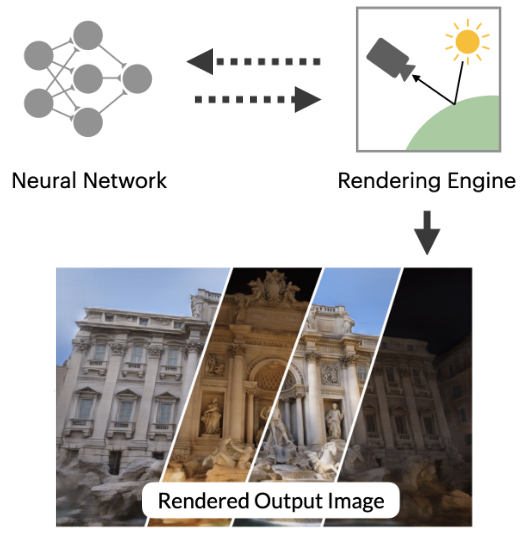
Advances in Neural Rendering
Eurographics State-of-the-Art Report 2022
*, Justus Thies*, Ben Mildenhall*, Pratul Srinivasan*, Edith Tretschk, Yifan Wang, Christoph Lassner, Vincent Sitzmann, Ricardo Martin-Brualla, Stepehen Lombardi, Tomas Simon, Christian Theobalt, Matthias Niessner, Jonathan T. Barron, Gordon Wetzstein, Michael Zollhoefer, and Vladislav Golyanik (* equal contribution)
[paper]

StyleVideoGAN: A Temporal Generative Model using a Pretrained StyleGAN
BMVC 2021 (Oral Presentation)
Gereon Fox, , Mohamed Elgharib, and Christian Theobalt
[project page] [paper]
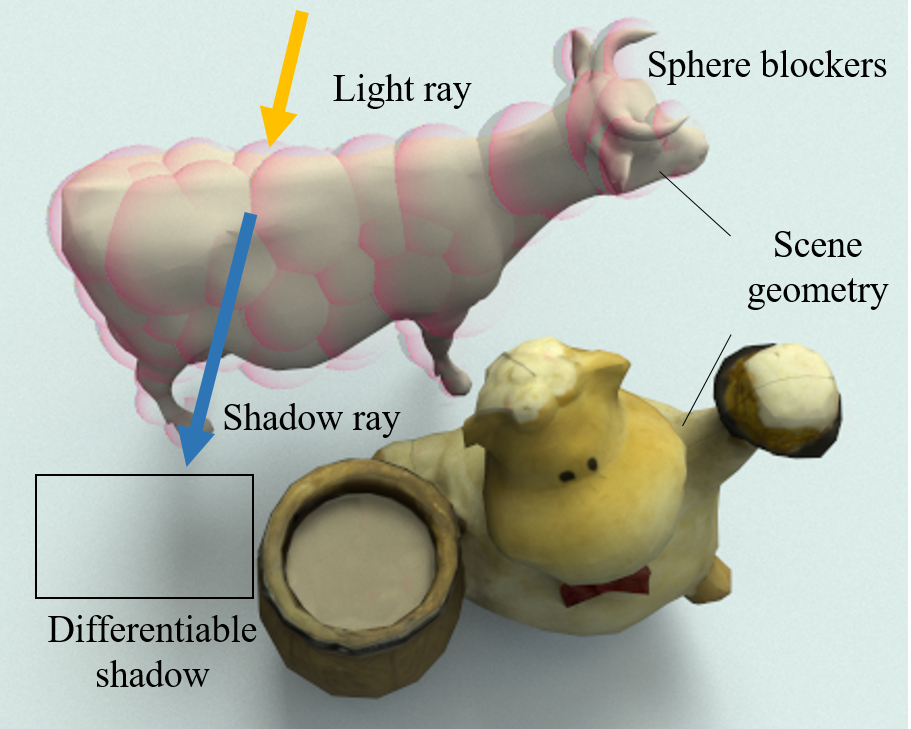
Efficient and Differentiable Shadow Computation for Inverse Problems
ICCV 2021
Linjie Lyu, Marc Habermann, Lingjie Liu, Mallikarjun B R, , and Christian Theobalt
[project page] [paper]
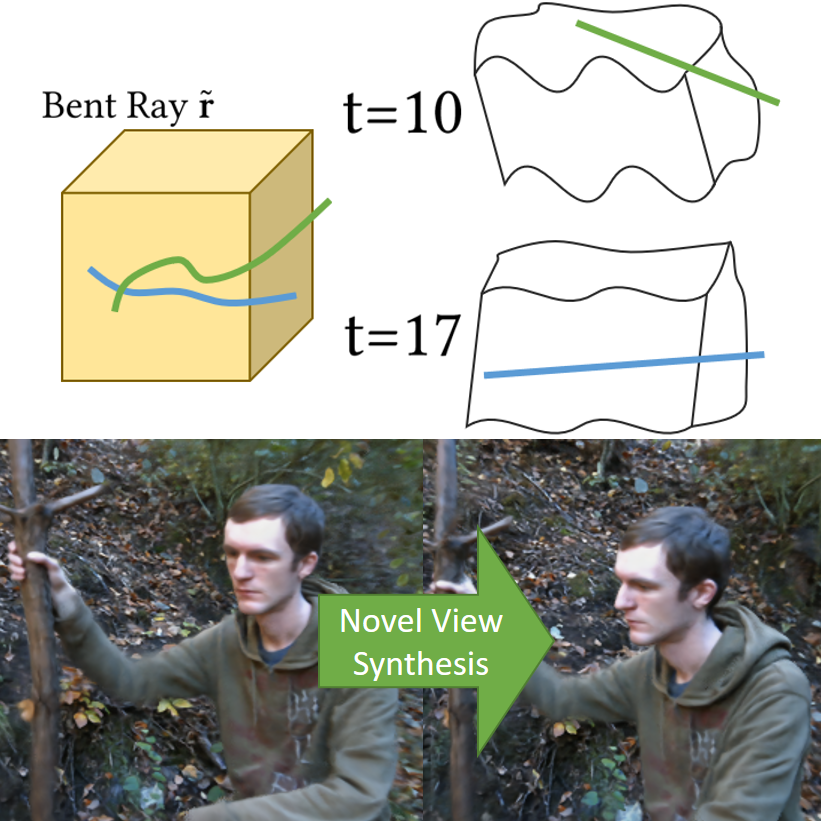
Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Deforming Scene from Monocular Video
ICCV 2021
Edith Tretschk, , Vladislav Golyanik, Michael Zollhoefer, Christoph Lassner, and Christian Theobalt
[project page] [paper] [code]

PhotoApp: Photorealistic Appearance Editing of Head Portraits
SIGGRAPH 2021
Mallikarjun B R, , Abdallah Dib, Tim Weyrich, Bernd Bickel, Hans-Peter Seidel, Hanspeter Pfister, Wojciech Matusik, Louis Chevallier, Mohamed Elgharib, and Christian Theobalt
[project page] [paper]

i3DMM: Deep Implicit 3D Morphable Model of Human Heads
CVPR 2021 (Oral Presentation)
Tarun Yenamandra, , Florian Bernard, Hans-Peter Seidel, Mohamed Elgharib, Daniel Cremers, and Christian Theobalt
[project page] [paper] [code]

Monocular Reconstruction of Neural Face Reflectance Fields
CVPR 2021
Mallikarjun B R, , Tae-Hyun Oh, Tim Weyrich, Bernd Bickel, Hans-Peter Seidel, Hanspeter Pfister, Wojciech Matusik, Mohamed Elgharib, and Christian Theobalt
[project page] [paper]

Learning Complete 3D Morphable Face Models from Images and Videos
CVPR 2021
Mallikarjun B R, , Hans-Peter Seidel, Mohamed Elgharib, and Christian Theobalt
[project page] [paper]

Monocular Real-time Full Body Capture with Inter-part Correlations
CVPR 2021
Yuxiao Zhou, Marc Habermann, Ikhsanul Habibie, , Christian Theobalt, and Feng Xu
[project page] [paper]

3D Morphable Face Models - Past, Present and Future
ACM Transactions on Graphics 2021
Bernhard Egger, Will Smith, , Stefanie Wuhrer, Michael Zollhoefer, Thabo Beeler, Florian Bernard, Timo Bolkart, Adam Kortylewski, Sami Romdhani, Christian Theobalt, Volker Blanz, and Thomas Vetter
[paper]

Egocentric Videoconferencing
SIGGRAPH Asia 2020
Mohamed Elgharib*, Mohit Mendiratta*, Justus Thies, Matthias Niessner, Hans-Peter Seidel, , Vladislav Golyanik, and Christian Theobalt (* equal contribution)
[project page] [paper]
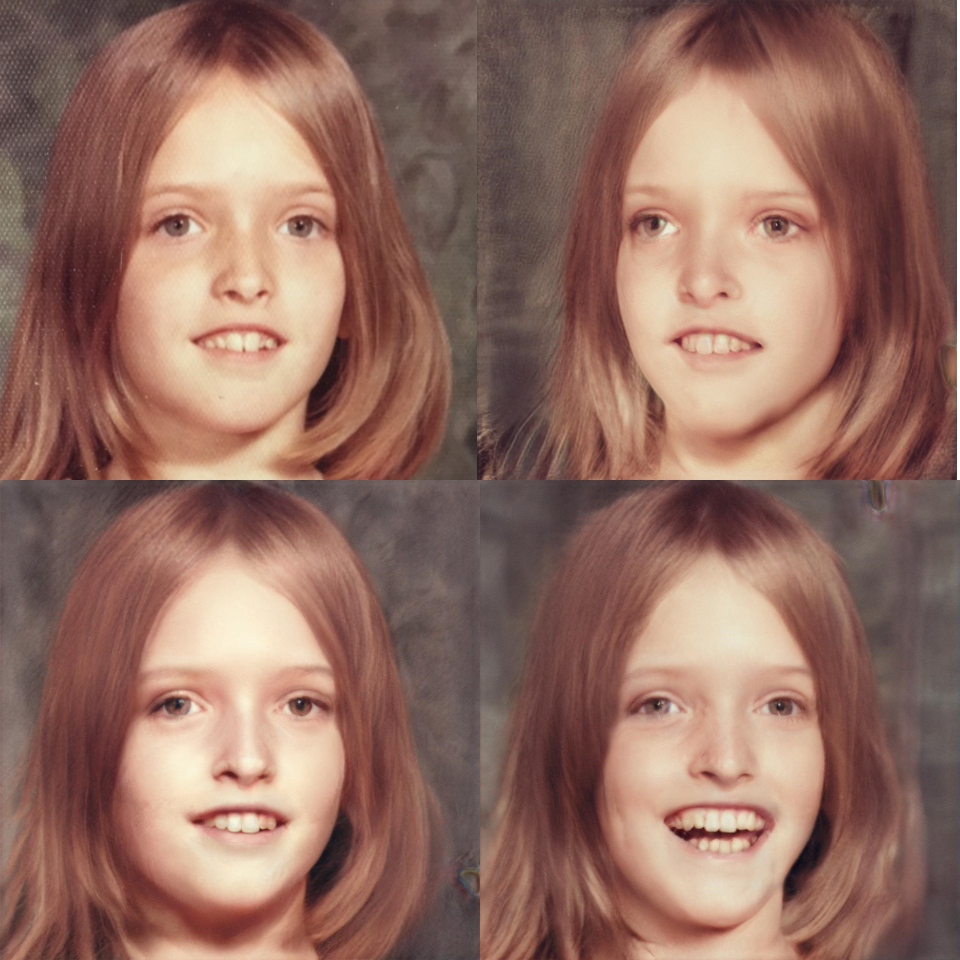
PIE: Portrait Image Embedding for Semantic Control
SIGGRAPH Asia 2020
, Mohamed Elgharib, Mallikarjun B R, Florian Bernard, Hans-Peter Seidel, Patrick Perez, Michael Zollhoefer, and Christian Theobalt
[project page] [paper]
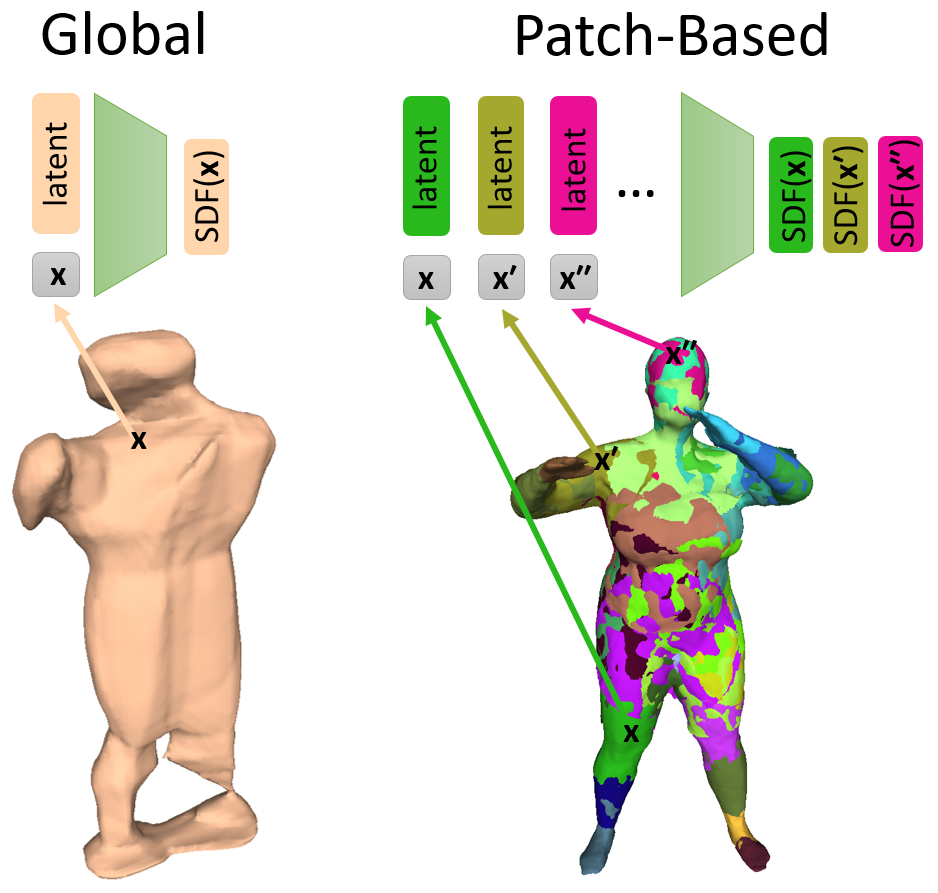
PatchNets: Patch-Based Generalizable Deep Implicit 3D Shape Representations
ECCV 2020
Edith Tretschk, , Michael Zollhoefer, Vladislav Golyanik, and Christian Theobalt
[project page] [paper]

Neural Voice Puppetry: Audio-driven Facial Reenactment
ECCV 2020
Justus Thies, Mohamed Elgharib, , Christian Theobalt, and Matthias Niessner
[project page] [paper] [code]

State of the Art on Neural Rendering
Eurographics State-of-the-Art Report 2020
*, Ohad Fried*, Justus Thies*, Vincent Sitzmann*, Stepehen Lombardi, Kalyan Sunkavalli, Ricardo Martin-Brualla, Tomas Simon, Jason Saragih, Matthias Niessner, Rohit Pandey, Sean Fanello, Gordon Wetzstein, Jun-Yan Zhu, Christian Theobalt, Maneesh Agrawala, Eli Schectman, Dan B Goldman, and Michael Zollhoefer (* equal contribution)
[paper]

StyleRig: Rigging StyleGAN for 3D Control over Portrait Images
CVPR 2020 (Oral Presentation)
, Mohamed Elgharib, Gaurav Bharaj, Florian Bernard, Hans-Peter Seidel, Patrick Perez, Michael Zollhoefer, and Christian Theobalt
[project page] [paper]

Text-based Editing of Talking-head Video
SIGGRAPH 2019
Ohad Fried, , Michael Zollhoefer, Adam Finkelstein, Eli Schectman, Dan B Goldman, Kyle Genova, Zeyu Jin, Christian Theobalt, and Maneesh Agrawala
[project page] [paper]
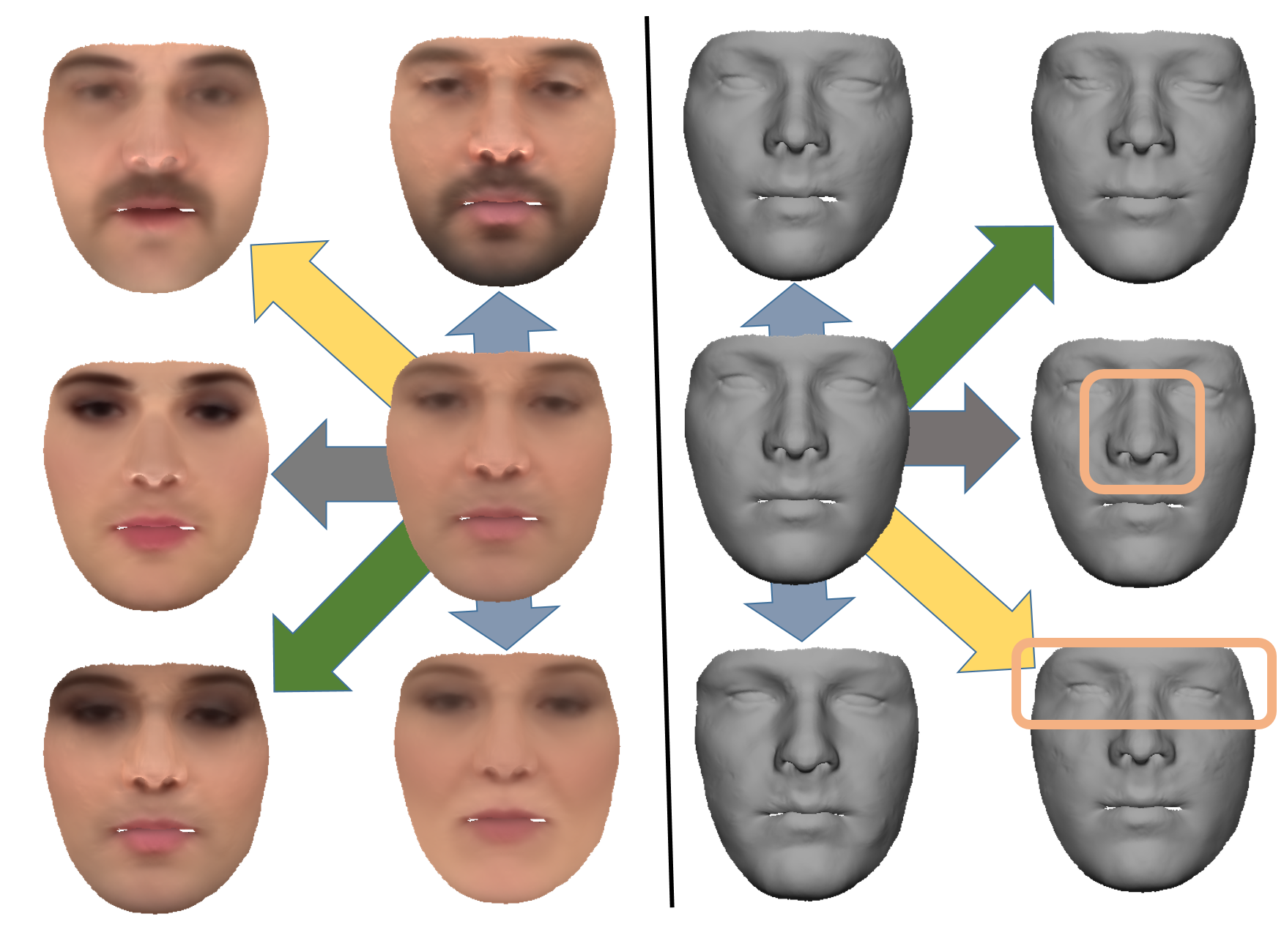
FML: Face Model Learning from Videos
CVPR 2019 (Oral Presentation)
, Florian Bernard, Pablo Garrido, Gaurav Bharaj, Mohamed Elgharib, Hans-Peter Seidel, Patrick Perez, Michael Zollhoefer, and Christian Theobalt
[project page] [paper]

High-Fidelity Monocular Face Reconstruction based on an Unsupervised Model-based Face Autoencoder
TPAMI 2018, special issue on The Best of ICCV 2017
, Michael Zollhoefer, Florian Bernard, Pablo Garrido, Hyeongwoo Kim, Patrick Perez, and Christian Theobalt
[project page] [paper]

A Hybrid Model for Identity Obfuscation by Face Replacement
ECCV 2018
Qianru Sun, , Weipeng Xu, Mario Fritz, Christian Theobalt, and Bernt Schiele
[project page] [paper]

Deep Video Portraits
SIGGRAPH 2018
Hyeongwoo Kim, Pablo Garrido, , Weipeng Xu, Justus Thies, Matthias Niessner, Patrick Perez, Christian Richardt, Michael Zollhoefer, and Christian Theobalt
[project page] [paper]

Self-supervised Multi-level Face Model Learning for Monocular Reconstruction at over 250 Hz
CVPR 2018 (Oral Presentation)
, Michael Zollhoefer, Pablo Garrido, Florian Bernard, Hyeongwoo Kim, Patrick Perez, and Christian Theobalt
[project page] [paper]

InverseFaceNet: Deep Single-Shot Inverse Face Rendering From A Single Image
CVPR 2018
Hyeongwoo Kim, Michael Zollhoefer, , Justus Thies, Christian Richardt, and Christian Theobalt
[project page] [paper]

MoFA: Model-based Deep Convolutional Face Autoencoder for Unsupervised Monocular Reconstruction
ICCV 2017 (Oral Presentation)
, Michael Zollhoefer, Hyeongwoo Kim, Pablo Garrido, Florian Bernard, Patrick Perez, and Christian Theobalt
[project page] [paper]
Theme inspired and adapted from tufte.css and Mathias Sablé-Meyer.